Technology
Cost-Effective GPU Utilization
Nov 21, 2025
Topic:
Implemented a time-sharing GPU scheduler that dynamically allocates GPU slices using 1 slice = 200mb ov vRAM for real-time inference demand. This optimization layer ensures GPU utilization remains above 90% during peak traffic. Creating systems like this to work with cluster autoscaling maintain balance and cost effective compute.
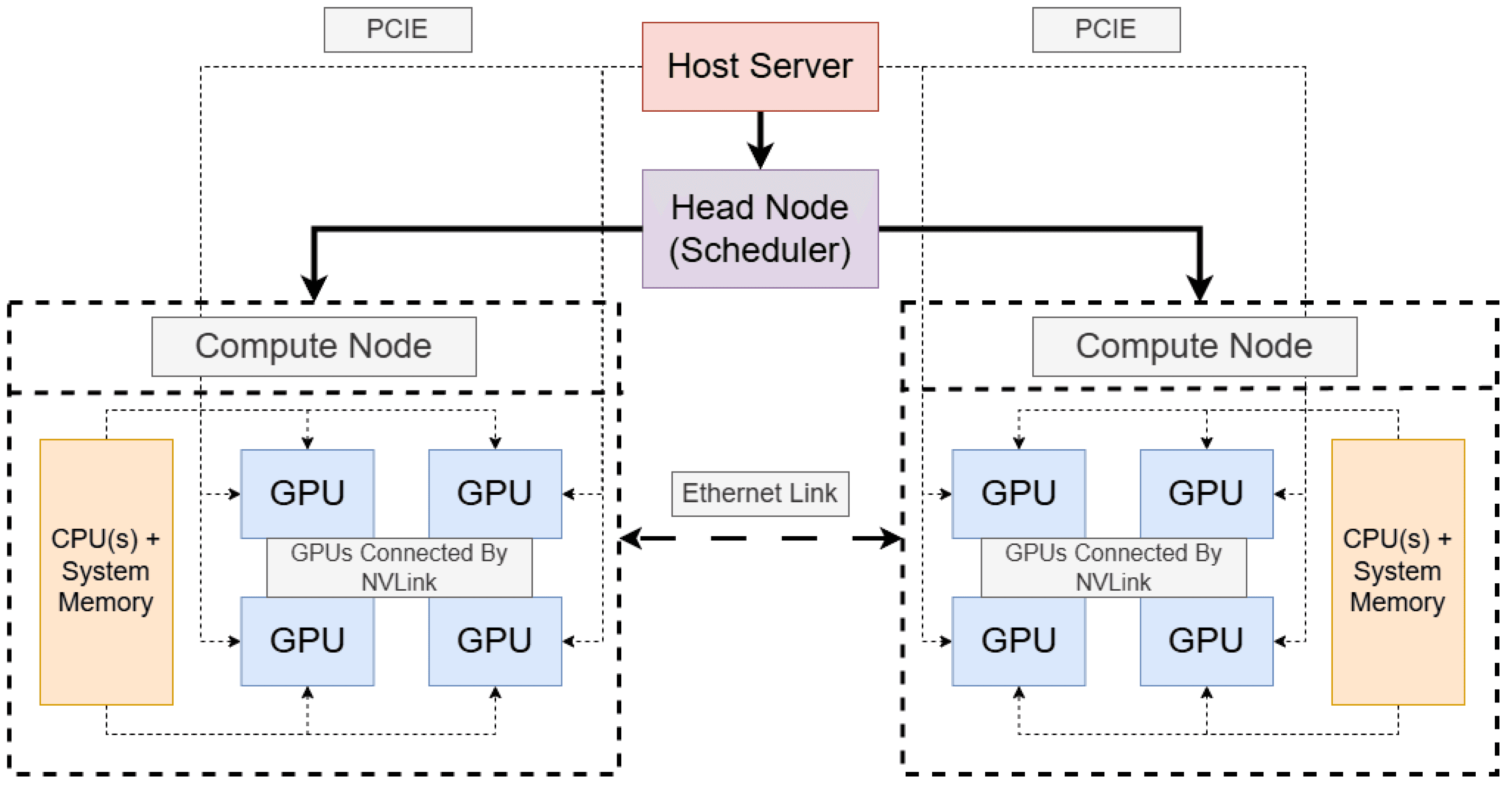
Why it matters:
Achieves enterprise-grade inference throughput at startup-level cost.
Enables continuous analysis of social data feeds without scaling compute.
Aligns KOAT’s infrastructure with sustainable AI operations and lower carbon footprint.